Clean data, confident decisions. Enterprise-grade data cleansing and validation.
Unify and cleanse your company’s data with intelligent cleaning and rules-based validation. Eliminate errors and duplicates, and build a stable, reliable data foundation for loading, migration and long-term operations.
Why clean data is critical for enterprise operations — and why manual handling isn’t enough?
Manual data handling creates errors, duplicates and fragmented structures — risking master data, partner records, reporting and migration. With our rules-based validation and dictionary-driven cleansing, we build a unified, transparent and hierarchically accurate dataset, ensuring every system operates on consistent, reliable data.

Why clean data is critical for enterprise operations — and why manual handling isn’t enough?
Manual data handling creates errors, duplicates and fragmented structures — risking master data, partner records, reporting and migration. With our rules-based validation and dictionary-driven cleansing, we build a unified, transparent and hierarchically accurate dataset, ensuring every system operates on consistent, reliable data.
Data only has value when it is clean, validated and consistent across every system — enabling stable and scalable operations.
Rules-based data
validation
Every field, type and logic rule is checked — errors are stopped before loading, and only consistent data enters your systems.
Dictionary-driven data cleansing
Automatic duplicate handling, similarity scoring and unified naming structure — faster preparation, minimal manual correction and consistent data across all records.
Consistent data view across all systems
Aligned and connected data everywhere — no mismatches, no manual reconciliation, only stable operations and more reliable reporting.
Clean, validated data is the first step toward reliable operations
The value of data lies not in volume, but in trust. A unified data model, automatically cleansed records and scalable data pipelines ensure every decision is based on one shared reality. Automation reduces errors, frees teams and accelerates decision-making — keeping the focus on value creation, not data fixing.
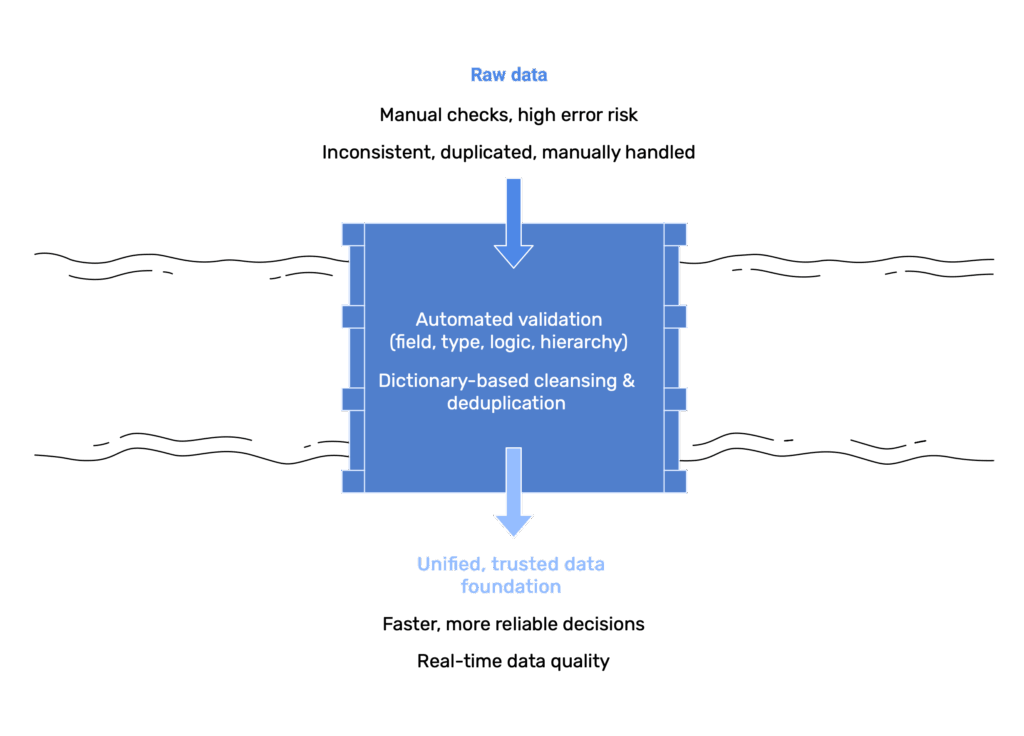
We don’t correct errors — we prevent them from being created
Data quality is not an after-the-fact check, but the result of a deliberately designed operating model. By mapping enterprise data structures, defining rules and applying rules-driven validation, we ensure incorrect or duplicate data never entersthe system. Corrections and approvals are handled on one interface, keeping data accurate, consistent and safe for migration, integration and daily operations. Clean data is not a task — it is the foundation.
Data mapping and rule definition
Understanding business and technical data structures, then building a unified validation logic. Rules are transparent, maintainable and scalable as your company grows.
Rules-based automated validation
Every record is automatically checked — field-level, logical and hierarchical validation. Issues surface before loading, so only correct, consistent data enters the process.
Dictionary-driven cleansing and duplicate handling
We standardize names and formats, detect duplicates and recommend merges. A clean, consistent database — up to ten times faster than manual work.
Transparent review and user control
Errors and suggested fixes are visible in one interface for review and approval. Every change is traceable, ensuring validated data is fully reliable for migration, integration and daily operations.
Related posts
See all
- AI In Business
- 7 mins

- AI In Business
- 10 mins

- AI In Business
- 6 mins